
Alors que l’utilisation des outils d’IA générative continue de croître, Meta ajoute de nouveaux contrôles qui permettront aux utilisateurs de refuser que leurs données personnelles soient incluses dans la formation du modèle d’IA, via un nouveau formulaire sur son hub Privacy Center.
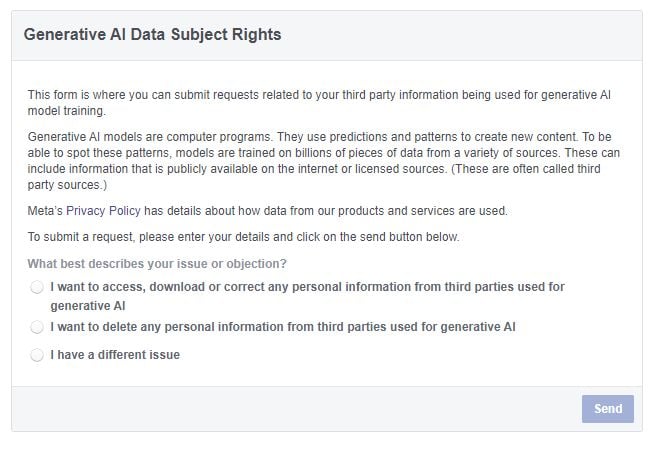
Comme vous pouvez le voir sur ce formulaire, Meta permettra désormais aux utilisateurs de «supprimer toutes les informations personnelles de tiers utilisées pour l’IA générative » via un simple processus de retour de formulaire, qui offrira plus de contrôle sur ceux-ci aux utilisateurs réguliers.
Meta a également ajouté un nouvel aperçu de l’IA générative dans son centre de confidentialité, qui comprend une description générale des différentes manières dont les modèles d’IA générative sont formés et du rôle que vos métadonnées peuvent jouer dans ce processus.
Selon Meta :
« Comme il faut une grande quantité de données pour enseigner des modèles efficaces, une combinaison de sources est utilisée pour la formation. Ces sources comprennent des informations accessibles au public en ligne et sous licence, ainsi que des informations provenant des produits et services de Meta. Lorsque nous collectons des informations publiques sur Internet ou des données sous licence auprès d’autres fournisseurs pour entraîner nos modèles, cela peut inclure des informations personnelles. Par exemple, si nous collectons un article de blog public, il peut inclure le nom et les coordonnées de l’auteur. Lorsque nous obtenons des informations personnelles dans le cadre de ces données publiques et sous licence que nous utilisons pour entraîner nos modèles, nous ne lions spécifiquement ces données à aucun compte Meta.»
Sur cette base, Meta cherche à sensibiliser les gens et à mieux contrôler cette utilisation.
« Nous avons la responsabilité de protéger la vie privée des personnes et disposons d’équipes dédiées à ce travail pour tout ce que nous construisons. Nous disposons d’un solide processus interne d’examen de la confidentialité qui permet de garantir que nous utilisons les données de Meta de manière responsable pour nos produits, y compris l’IA générative. Nous nous efforçons d’identifier les risques potentiels pour la vie privée qui impliquent la collecte, l’utilisation ou le partage d’informations personnelles et développons des moyens de réduire ces risques pour la vie privée des personnes.
Cette mise à jour intervient alors que les nouvelles règles DSA de l’UE entrent en vigueur, qui permettront également de mieux contrôler les données personnelles et la manière dont elles sont utilisées par les plateformes en ligne. En tant que tel, il se pourrait que Meta cherche à devancer les prochaines dispositions de l’UE avec cette mise à jour, le DSA spécifiant déjà que les plateformes sociales doivent fournir davantage d’options de contrôle des données en standard dans leurs applications.
Il semble inévitable que l’utilisation de l’IA générative soit également intégrée, tandis que de nombreux artistes font également pression en faveur de nouvelles lois qui leur permettraient de retirer leurs œuvres des ensembles de formation pour les modèles d’IA.
Même si cela reste une zone grise juridique. L’utilisation d’un contenu accessible au public pour créer quelque chose de nouveau, même si cette nouvelle création est dérivée, n’est pas une considération qui a été intégrée dans la loi sur le droit d’auteur en tant que telle, et il faudra un certain temps, et divers cas de test, pour mettre à jour les règles autour. utilisation involontaire ou non souhaitée. En tant que tel, offrir aux gens la possibilité de supprimer leurs propres informations et de travailler deviendra une priorité beaucoup plus importante à l’avenir, ce que Meta cherche à prendre une longueur d’avance ici.
Meta note également qu’elle envisage de faire bientôt un pas plus important dans le domaine de l’IA générative.
« Nous investissons énormément dans ce domaine parce que nous croyons aux avantages que l’IA générative peut apporter aux créateurs et aux entreprises du monde entier. Pour former des modèles efficaces afin de débloquer ces avancées, une quantité importante d’informations est nécessaire provenant de sources accessibles au public et sous licence. Nous conservons les données de formation aussi longtemps que nous en avons besoin, au cas par cas, pour garantir qu’un modèle d’IA fonctionne de manière appropriée, sûre et efficace. Nous pouvons également les conserver pour protéger nos intérêts ou ceux d’autrui, ou pour nous conformer à des obligations légales.»
Vous pouvez vous attendre à ce que les réglementations d’utilisation autour de l’IA générative évoluent rapidement, surtout maintenant que le secteur très controversé de l’édition de disques est impliqué.
Dans cet esprit, il est logique que Meta anticipe le prochain grand changement.
Vous pouvez lire l’aperçu complet de l’utilisation des données « Confidentialité et IA générative » de Meta ici.

