
Au milieu d'un débat en cours sur les paramètres qui devraient être définis autour de l'IA générative et sur la manière dont elle est utilisée, Meta s'est récemment associé à Laboratoire de démocratie délibérative de Stanford mener une forum communautaire sur l'IA générativeafin de recueillir les commentaires des utilisateurs réels sur leurs attentes et leurs préoccupations concernant le développement responsable de l'IA.
Le forum a incorporé des réponses de plus de 1 500 personnes du Brésil, d'Allemagne, d'Espagne et des États-Unis, et s'est concentré sur les principaux problèmes et défis que les gens voient dans le développement de l'IA.
Et il existe quelques notes intéressantes sur la perception du public de l’IA et de ses avantages.
Les premiers résultats, tels que soulignés par Meta, montrent que :
- La majorité des participants de chaque pays estiment que l’IA a eu un impact positif
- La majorité estime que les chatbots IA devraient pouvoir utiliser les conversations passées pour améliorer les réponses, à condition que les gens soient informés.
- La majorité des participants pensent que les chatbots IA peuvent ressembler à des humains, à condition que les gens soient informés.
Bien que le détail spécifique soit intéressant.
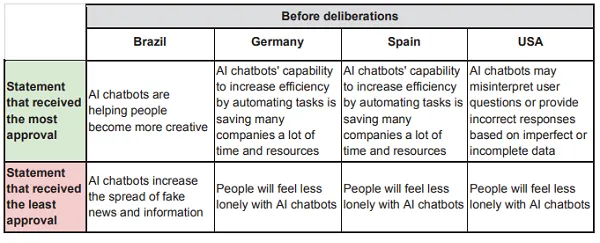
Comme vous pouvez le voir dans cet exemple, les déclarations qui ont suscité le plus de réponses positives et négatives étaient différentes selon la région. De nombreux participants ont changé d’avis sur ces éléments tout au long du processus, mais il est intéressant de considérer où les gens voient actuellement les avantages et les risques de l’IA.
Le rapport examine également les attitudes des consommateurs à l’égard de la divulgation de l’IA et la provenance des outils d’IA pour obtenir leurs informations :
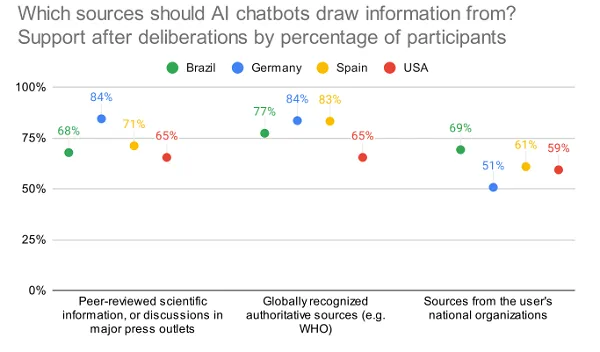
Il est intéressant de noter que ces sources sont relativement peu approuvées aux États-Unis.
Il existe également des informations permettant de savoir si les gens pensent que les utilisateurs devraient pouvoir entretenir des relations amoureuses avec les chatbots IA.
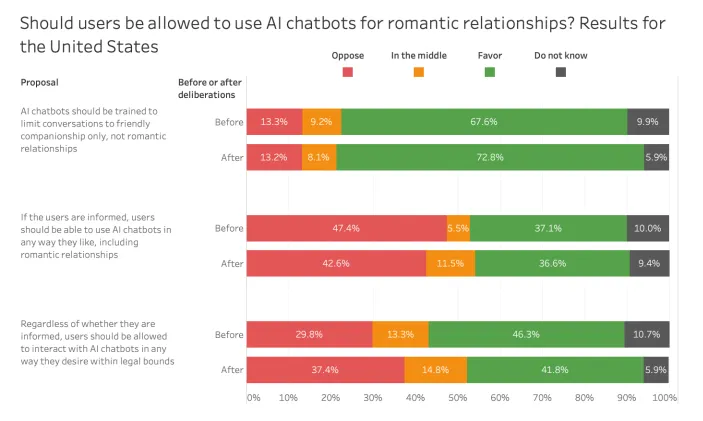
Un peu bizarre, mais c’est une progression logique et quelque chose qui devra être pris en compte.
Une autre considération intéressante du développement de l’IA qui n’est pas spécifiquement soulignée dans l’étude concerne les contrôles et les pondérations que chaque fournisseur met en œuvre dans ses outils d’IA.
Google a récemment été contraint de s'excuser pour les résultats trompeurs et non représentatifs produits par son système Gemini, qui penchait trop vers une représentation diversifiée, tandis que le modèle Llama de Meta a également été critiqué pour produire des représentations plus aseptisées et politiquement correctes basées sur certaines invites.
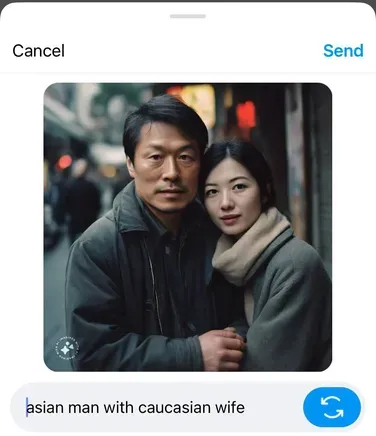
Des exemples comme celui-ci mettent en évidence l’influence que les modèles eux-mêmes peuvent avoir sur les résultats, ce qui constitue une autre préoccupation majeure dans le développement de l’IA. Les entreprises devraient-elles avoir un tel contrôle sur ces outils ? Faut-il une réglementation plus large pour garantir une représentation égale et un équilibre dans chaque outil ?
Il est impossible de répondre à la plupart de ces questions, car nous ne comprenons pas encore pleinement la portée de ces outils ni comment ils pourraient influencer une réponse plus large. Mais il devient clair que nous avons besoin de mettre en place des garde-fous universels afin de protéger les utilisateurs contre la désinformation et les réponses trompeuses.
En tant que tel, il s’agit d’un débat intéressant, et il vaut la peine d’examiner ce que les résultats signifient pour le développement plus large de l’IA.
Vous pouvez lire le rapport complet du forum ici.


